

The generic large Vision-Language Models (VLMs) is rapidly developing, but still perform poorly in Remote Sensing (RS) domain, which is due to the unique and specialized nature of RS imagery and the comparatively limited spatial perception of current VLMs. Existing Remote Sensing specific Vision Language Models (RSVLMs) still have considerable potential for improvement, primarily owing to the lack of large-scale, high-quality RS vision-language datasets. We constructed HqDC-1.4M, the large scale High quality and Detailed Captions for RS images, containing 1.4 million image-caption pairs, which not only enhance the RSVLM's understanding of RS images but also significantly improve the model's spatial perception abilities, such as localization and counting, thereby increasing the helpfulness of the RSVLM. Moreover, to address the inevitable "hallucination" problem in RSVLM, we developed RSSA, the first dataset aimed at enhancing the Self-Awareness capability of RSVLMs. By incorporating a variety of unanswerable questions into typical RS visual question-answering tasks, RSSA effectively improves the truthfulness and reduces the hallucinations of the model's outputs, thereby enhancing the honesty of the RSVLM. Based on these datasets, we proposed the H2RSVLM, the Helpful and Honest Remote Sensing Vision Language Model. H2RSVLM has achieved outstanding performance on multiple RS public datasets and is capable of recognizing and refusing to answer the unanswerable questions, effectively mitigating the incorrect generations.
We utilized the gemini-1.0-pro-vision API to generate descriptions for images from multiple public RS datasets, thereby obtaining a dataset of image-text pairs to serve as the pre-training data for RSVLMs.


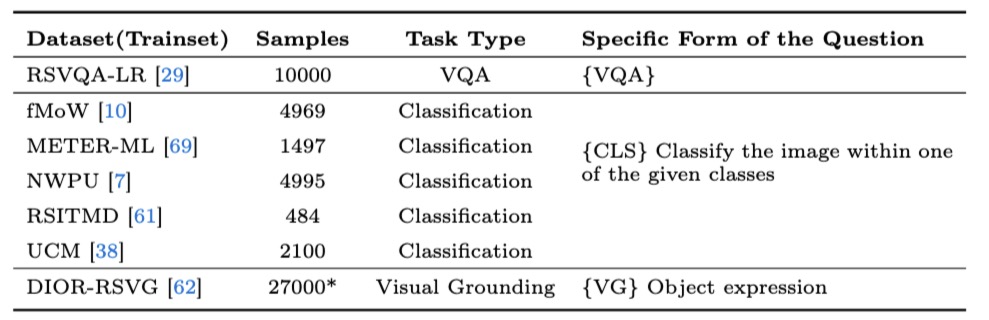
The training instrutions during the Supervised Fine Tuning (SFT) stage comprises four parts, each with a specified quantity: the HqDC-Instruct dataset (30k), the RSSA dataset (44k), the RS-Specialized-Instruct dataset (29.8k), and the RS-ClsQaGrd-Instruct dataset (78k), summing up to a total of 180k



We adopted the LLaVA model and continued to train it to obtain the H2 It includes three main components: (1) A pretrained vision encoder using the CLIP-Large model, with a resolution of 336 × 336 and a patch size of 14, capable of converting input images into 576 tokens. (2) An LLM based on the open-source Vicuna-v1.5, originating from LLaMA2. We use the 7B-version throughout this paper. (3) It incorporates a projector, which is a multilayer perceptron composed of two layers, used to connect the vision encoder and the LLM.








@misc{pang2024h2rsvlm,
title={H2RSVLM: Towards Helpful and Honest Remote Sensing Large Vision Language Model},
author={Chao Pang and Jiang Wu and Jiayu Li and Yi Liu and Jiaxing Sun and Weijia Li and Xingxing Weng and Shuai Wang and Litong Feng and Gui-Song Xia and Conghui He},
year={2024},
eprint={2403.20213},
archivePrefix={arXiv},
primaryClass={cs.CV}
}